Model organism/genome databases (MODs) produce gene pages of similar gene data, and may benefit from looking at unifying these to common structure, labelling, etc.
Gene page attributes that have been discussed for inclusion in include Names, symbols/IDs, synonyms; Map locations; Sequences and Reagents; Gene ontology; Similar Genes; Database cross-refs and external links; Alleles and Transcripts; Proteins, Structure and Domains; Expression and Mutant Phenotypes; Gene Interactions; Literature references; and Summary Text
One outline for these attributes is to have main sections as:
BASIC_INFORMATION, LOCATION, GENE_PRODUCT, GENE_ONTOLOGY,
SIMILAR_GENES, FUNCTION, REAGENTS, VARIANTS, LITERATURE,
SUMMARY, ADDITIONAL_INFORMATION
Discussion at the July 2008 GMOD Meeting resulted in the Bio%253A%253AGMOD::GenericGenePage Perl abstract class that can be used by organizations to generate common gene pages in XML format.
From Dongilbert 13:15, 14 July 2008 (EDT) :
In hopes there will be a lively discussion on this topic at the July 2008 GMOD Meeting here are some thoughts. I would like to attend, but instead will be later in the week at the ISMB 2008 Toronto meeting, and hope to hear some outcomes of this.
It seems to me the only real issue in moving forward with a common gene page, is how to convince MOD projects to adopt the same gene summary format for our many shared customers. I’d like to see an agreement among 2+ genome data providers to actually produce and deploy a common gene report (or such data files) within the coming year.
There is a history in genome informatics of everyone doing their own thing across projects with common genome data and common customer needs. Some efforts do achieve common usage and consensus: GFF(3) format, GBrowse, Chado schema/db, Apollo annotator among others.
This common gene report concept to date is to provide consumers of genome data with the format across projects, both for web display and for simple computing. It is aimed at simple summaries of gene data, structured in a common way for many organisms, suitable bioscientists and students to read and use as web pages and data files (XML) and do simple computing on if desired. One can see it as alternate option to a MOD project’s full, project-specific documents. It isn’t aimed at full, complex data exchange among databases. Other formats/methods exist for that.
Although there are engineering details for implementing this for any project, this isn’t likely to be a large effort. We were able to use simple web-page scraping software to convert existing MOD gene reports into a common format (see http://eugenes.org/gmod/gene-report-examples/)
User-interface and web page design aspects can be tuned to each MOD’s desires. The main thrust is of a common gene page is having common data labelled in a similar way. Agreement on an XML notation should follow in a straightforward way from common data fields. I (dgg) will be happy to work on this with any group of MODs who agree to deploy a common gene report. Prior software and example UGP-XML cases can be adapted to help with this.
See the Common Gene Page section of the July 2008 GMOD Meeting notes. This discussion resulted in implementation of the Bio%253A%253AGMOD::GenericGenePage Perl abstract class.
See this folder for some discussion, documents and examples for MOD gene pages from 2004: http://eugenes.org/gmod/gene-report-examples/
See this blog entry on a 2005 meeting disccussion, http://blog.gmod.org/common_gene_pages
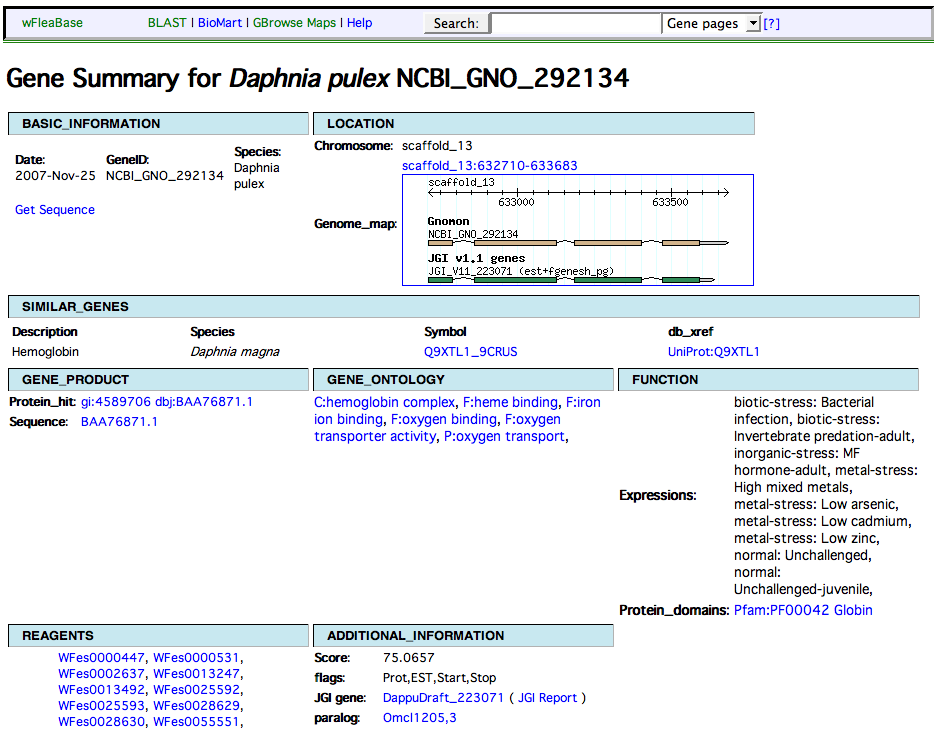
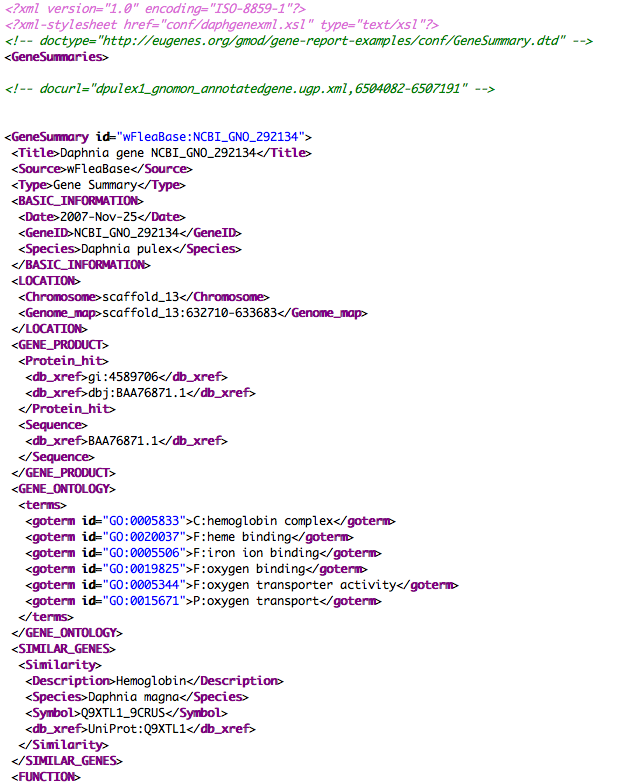
There is an implementation of how this can be used at Daphnia-base, where the gene reports are structured XML, with a style sheet to display. For example, see this gene page, http://wfleabase.org/lucegene/lookup?id=NCBI_GNO_292134 (view the page source to see structured gene page XML). Or see these screen shots daphnia gene page and gene page xml.
There is a simple perl tool to turn annotated GFF data into
this gene page XML, suitable for search and display, in
GMOD genepages in SVN or
http://eugenes.org/gmod/gene-report-examples/ for
bin/gff2ugpxml.pl.
Search and display is then provided by the GMOD LuceGene tool, detailed at LuceGene_for_Daphnia_genome.
A new Pea aphid genome annotation at http://insects.eugenes.org/aphid/ offers rapid access to computed gene models, putative functions and database accession matches.
Automated annotation of new genomes generates much useful information. Biologists need to sift through and making sense of these annotations, to learn what makes sense and is new or specific to that species. However the computed annotations often generate a large amount of heterogenous data, from BLAST matches to homologous proteins, to EST data, several gene predictions, and associated genome features. It takes a significant bioinformatics effort to arrange these into a common database structure for management. In the mean time, the biologists who can most benefit from the details are often left waiting for computational details.
One option for rapid access to computed gene annotations is to collect these into a common gene page structure. Within a common gene page framework the various sequence accessions, gene model evidence, protein function annotations, and such can be stored and presented for searching and reports. Biological discovery can proceed using such draft annotations.
{kind=link}
{kind=link}