Daphnia’s genome now has lots of gene annotations, wanting both search and reporting for these. I’ve dusted off LuceGene which is designed for this, and installed over the Labor Day weekend at http://wfleabase.org/lucegene/. It was relatively easy to do: most of my time was in designing an XSLT stylesheet for gene page display. Other organism databases should be able to follow these steps, with more detail forthcoming, and have a similar gene search and report service without special effort.
Steps involved
bin/gff2ugpxml.pl. This is Daphnia specific, but should be easy to
revise for other species GFF. You also want the lib/ and conf/
sections here to generate UGP-XML. See also the
genepages project in
SVN.conf/ugpxml.* configuration files, tweaking for
Daphnia. The ugpxml.properties handles Lucegene indexing
configuration, and that mostly worked but needed some field updates
for Daphnia. The ugpxml.xslt for GeneSummary page reports needed the
most work, to tune it to the specific gene annotations for this data
set.admin/lucegene-index.sh script to index the gene page XML,
fasta sequences and web documents (or use admin/make-indices for
all).Note that this is all what-you-see-is-what-you-get, in that the source gene page XML is exactly what is being searched, with no hidden or extra search tables, and is exactly what is sent to the client web browser. The browser does the boring job of converting it to HTML display (if it wants). Or one can use these gene pages in XML for data processing without tedious HTML page scraping.
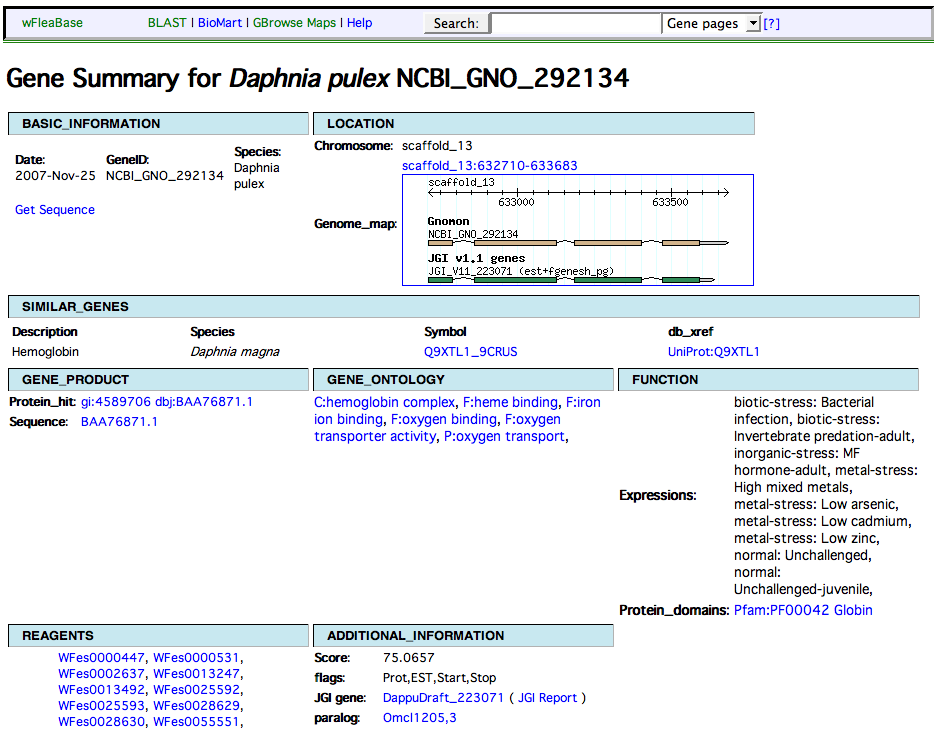
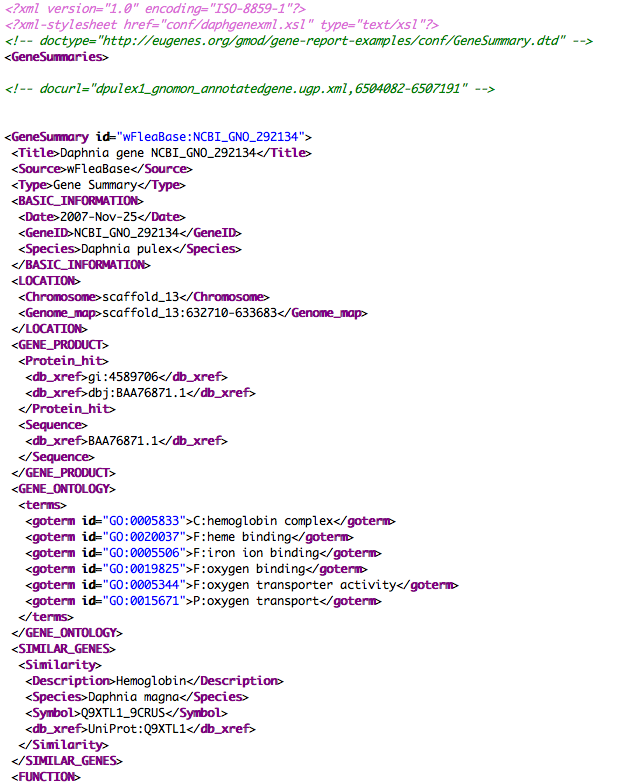
Here is a Daphnia gene page example, http://wfleabase.org/lucegene/lookup?id=NCBI_GNO_292134 (view the page source to see structured gene page XML). This corresponds to these screen shots daphnia gene page and gene page xml.
Dongilbert 16:23, 4 September 2007 (EDT)
{kind=link}
{kind=link}